Perceptrón multicapa
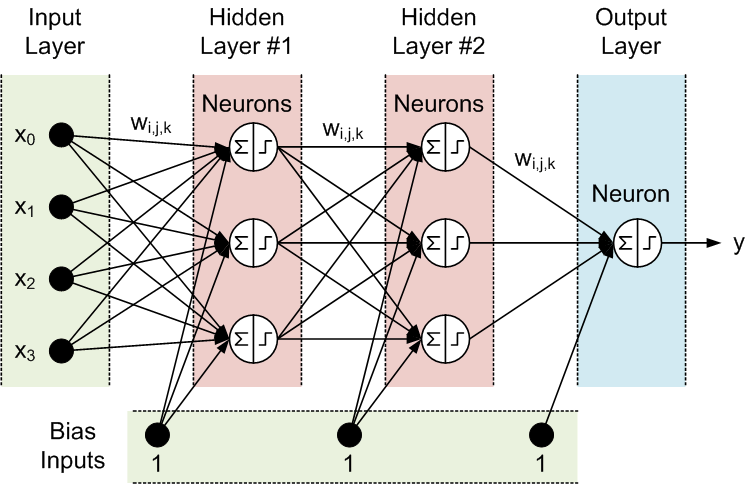
A diferencia del perceptrón simple que hemos visto hasta ahora, lo normal es que una red neuronal esté compuesta por múltiples unidades o neuronas que intervienen a distintos niveles (capas ocultas) de procesamiento desde la entrada de la señal hasta la salida, y por eso se habla de perceptrón multiple o multicapa.
Entonces se puede hablar de:
- Una capa de entrada con una o varias fuentes de entrada. Como esta capa no hace ningún proceso, sólo recibe los datos de entrada, no suele cuantificarse y la capa 0 es la primera capa oculta.
- Una o más capas ocultas (capas 0, 1, 2...), cada una con un número variable de neuronas.
- Una capa de salida con un número variable de neuronas que producen las señales de salida de la red neuronal.
Al igual que en el caso del perceptrón simple, aquí también se trata de ajustar los pesos para averiguar el resultado de salida, solo que ahora se complica por las múltiples relaciones entre las neuronas de capas consecutivas.
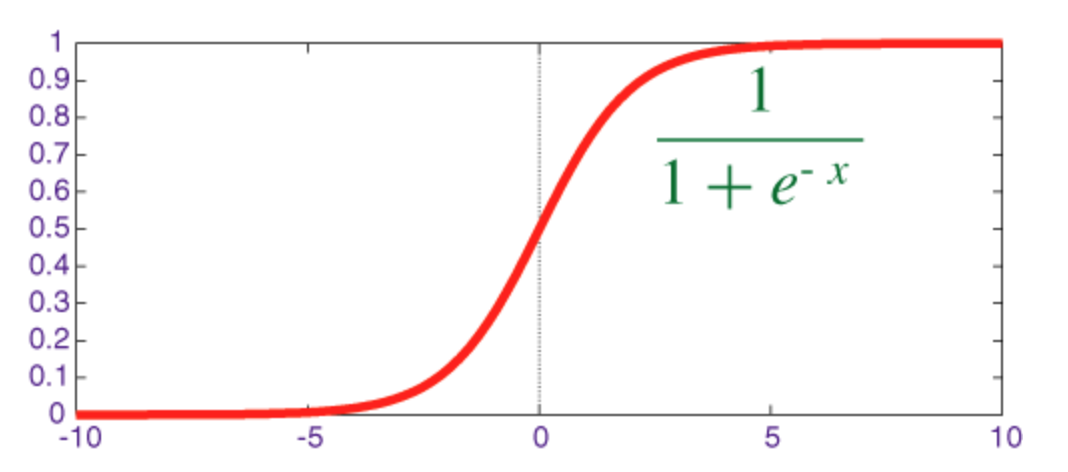
Para calcularlos hay que tener en cuenta la capa a la que llega la conexión y las neuronas inicial y destino, y además entra en juego la función sigmoide (función de aplastamiento cuya salida está en el rango 0 - 1) como función de activación de la neurona. Esta función se utiliza para asignar los nodos de entrada a los nodos de salida, esto es, para impartir no linealidad a la salida de una capa de red neuronal.
El siguiente código escrito en Dart es una adaptación, con pequeñas variaciones formales, del código original en C# de Rafael Alberto Moreno Parra publicado en 'Redes Neuronales 2020' (CC BY) para calcular los pesos en un perceptron multicapa.
Básicamente el código contempla tres clases: Perceptron, Capas y Neuronas y calcula la salida para una lista de pesos y umbrales utilizando la función sigmoide. En el proceso de entrenamiento se realiza un proceso iterativo de propagación hacia atrás (backpropagation) en el que inicialmente se obtienen las predicciones de la red con los valores actuales y posteriormente se corrigen con los pesos propagando el error (error cuadrático medio) que se comete hacia atrás.
Los ajustes básicos de este entrenamiento incluyen una tasa de aprendizaje y un número de iteraciones (ciclos) de entrenamiento. Se ha añadido una tercera variable que permite detener el proceso sin realizar todos los ciclos cuando el proceso de aprendizaje se considera completado (para eso no es suficente que la salida sea correcta, el margen de error debe ser menor al mínimo establecido).
import 'dart:io';
import 'dart:math';
// ajustes generales del aprendizaje
final tasaAprendizaje = 0.3;
var ciclos = 8000;
final errorParada = 0.1; // error máximo que considera completado el aprendizaje
void main(List<String> arguments) {
var tablaInput = [
[1, 1],
[1, 0],
[0, 1],
[0, 0]
];
var tablaOut = [0, 1, 1, 0];
var redNeuronal = [2, 3, 4, 1]; // número de neuronas en entrada y capas
var perceptron = Perceptron(redNeuronal);
var entradas = perceptron.entradas;
var salidaEsperada = <double>[0];
print('TABLA XOR\tSALIDA\tVALOR\t\tERROR');
var stop = false;
var aprendizajeTabla = 0;
for (var ciclo = 1; ciclo <= ciclos; ciclo++) {
if (ciclo % 400 == 0 || ciclo == 1) print('Ciclo: $ciclo');
for (var fila = 0; fila < tablaInput.length; fila++) {
for (var n = 0; n < entradas.length; n++) {
entradas[n] = tablaInput[fila][n].toDouble();
}
salidaEsperada[0] = tablaOut[fila].toDouble();
perceptron
..calculaSalida(entradas)
..entrena(entradas, salidaEsperada);
if (ciclo == 1 || (ciclo % 400 == 0 && stop == false)) {
perceptron.salidaPerceptron(entradas, salidaEsperada[0]);
}
if (perceptron.checkAprendizaje(salidaEsperada[0]) == true) {
aprendizajeTabla++;
if (aprendizajeTabla > 3 && stop == true) {
perceptron.salidaPerceptron(entradas, salidaEsperada[0]);
ciclos = ciclo;
}
} else {
aprendizajeTabla = 0;
}
}
if (aprendizajeTabla > 3 && stop == false) {
stop = true;
print('Ciclo: $ciclo - Aprendizaje completado.');
}
}
print('Fin');
}
class Neurona {
var pesos = <double>[];
var nuevosPesos = <double>[];
double umbral;
double nuevoUmbral;
Neurona(Random random, int totalEntradas) {
for (var i = 0; i < totalEntradas; i++) {
pesos.add((random.nextDouble()));
nuevosPesos.add((0.0));
}
umbral = random.nextDouble();
nuevoUmbral = 0.0;
}
double calculaSalida(List<double> entradas) {
double sigmoide(x) => 1 / (1 + exp(-x));
var valor = 0.0;
for (var i = 0; i < pesos.length; i++) {
valor += entradas[i] * pesos[i];
}
valor += umbral;
return sigmoide(valor);
}
void actualiza() {
pesos = List.from(nuevosPesos);
umbral = nuevoUmbral;
}
}
class Capa {
var neuronas = <Neurona>[];
var salidas = <double>[];
Capa(Random random, int totalNeuronas, int totalEntradas) {
for (var i = 0; i < totalNeuronas; i++) {
neuronas.add(Neurona(random, totalEntradas));
salidas.add(0.0);
}
}
void calculaCapa(List<double> entradas) {
for (var i = 0; i < neuronas.length; i++) {
salidas[i] = neuronas[i].calculaSalida(entradas);
}
}
void actualiza() {
for (var i = 0; i < neuronas.length; i++) {
neuronas[i].actualiza();
}
}
}
class Perceptron {
var entradas = <double>[];
var capas = <Capa>[];
Perceptron(List<int> numCapas) {
entradas = List.generate(numCapas[0], (i) => 0);
var random = Random();
for (var i = 0; i < numCapas.length - 1; i++) {
capas.add(Capa(random, numCapas[i + 1], numCapas[i]));
}
}
void salidaPerceptron(List<double> entradas, double salidaEsperada) {
for (var i = 0; i < entradas.length; i++) {
stdout.write('${entradas[i].toInt()} | ');
}
stdout.write('${salidaEsperada.toInt()} | ');
for (var i = 0; i < capas[2].salidas.length; i++) {
var salida = capas[2].salidas[i] >= 0.5 ? 1 : 0;
var valor = capas[2].salidas[i];
var error = (salidaEsperada - valor).abs();
stdout.write('\t$salida\t${valor.toStringAsFixed(5)}\t\t${error.toStringAsFixed(5)}\n');
}
}
void calculaSalida(List<double> entradas) {
for (var i = 0; i < capas.length; i++) {
if (i == 0) {
capas[i].calculaCapa(entradas);
continue;
}
capas[i].calculaCapa(capas[i - 1].salidas);
}
}
bool checkAprendizaje(double salidaEsperada) {
for (var i = 0; i < capas[2].salidas.length; i++) {
var valor = capas[2].salidas[i];
var error = (salidaEsperada - valor).abs();
if (error > errorParada) {
return false;
}
}
return true;
}
void entrena(List<double> entradas, List<double> salidaEsperada) {
var neuronasCapa = List.generate(capas.length, (i) => capas[i].neuronas.length);
double errorSuma({double peso = 1}) {
var error = 0.0;
for (var i = 0; i < neuronasCapa[2]; i++) {
var yi = capas[2].salidas[i];
var si = salidaEsperada[i];
error += peso * (yi - si) * yi * (1 - yi);
}
return error;
}
double dError(double sumaError, {double input, double out0, double out1}) {
if (input == null && out0 == null) return out1 * sumaError;
if (input == null) return out0 * out1 * (1 - out1) * sumaError;
return input * out0 * (1 - out0) * sumaError;
}
double dErrorUmbral(double sumaError, double out) =>
out * (1 - out) * sumaError;
double ajustePeso(double peso, double dError) =>
peso - tasaAprendizaje * dError;
// procesa pesos capa 2
for (var j = 0; j < neuronasCapa[1]; j++) {
for (var i = 0; i < neuronasCapa[2]; i++) {
var dE2 = dError(errorSuma(), out1: capas[1].salidas[j]);
capas[2].neuronas[i].nuevosPesos[j] =
ajustePeso(capas[2].neuronas[i].pesos[j], dE2);
}
}
//procesa pesos capa 1
for (var j = 0; j < neuronasCapa[0]; j++) {
for (var k = 0; k < neuronasCapa[1]; k++) {
var acum = 0.0;
for (var i = 0; i < neuronasCapa[2]; i++) {
acum += errorSuma(peso: capas[2].neuronas[i].pesos[k]);
}
var dE1 = dError(acum, out0: capas[0].salidas[j], out1: capas[1].salidas[k]);
capas[1].neuronas[k].nuevosPesos[j] =
ajustePeso(capas[1].neuronas[k].pesos[j], dE1);
}
}
// procesa pesos capa 0
for (var j = 0; j < entradas.length; j++) {
for (var k = 0; k < neuronasCapa[0]; k++) {
var acumular = 0.0;
for (var p = 0; p < neuronasCapa[1]; p++) {
var acum = 0.0;
for (var i = 0; i < neuronasCapa[2]; i++) {
acum += errorSuma(peso: capas[2].neuronas[i].pesos[p]);
}
var w1kp = capas[1].neuronas[p].pesos[k];
var a1p = capas[1].salidas[p];
acumular += w1kp * a1p * (1 - a1p) * acum;
}
var dE0 = dError(acumular, input: entradas[j], out0: capas[0].salidas[k]);
capas[0].neuronas[k].nuevosPesos[j] =
ajustePeso(capas[0].neuronas[k].pesos[j], dE0);
}
}
// procesa umbrales capa 2
for (var i = 0; i < neuronasCapa[2]; i++) {
var dE2 = errorSuma();
capas[2].neuronas[i].nuevoUmbral =
ajustePeso(capas[2].neuronas[i].umbral, dE2);
}
// procesa umbrales capa 1
for (var k = 0; k < neuronasCapa[1]; k++) {
var acum = 0.0;
for (var i = 0; i < neuronasCapa[2]; i++) {
acum += errorSuma(peso: capas[2].neuronas[i].pesos[k]);
}
var dE1 = dErrorUmbral(acum, capas[1].salidas[k]);
capas[1].neuronas[k].nuevoUmbral =
ajustePeso(capas[1].neuronas[k].umbral, dE1);
}
// procesa umbrales capa 0
for (var k = 0; k < neuronasCapa[0]; k++) {
var acumular = 0.0;
for (var p = 0; p < neuronasCapa[1]; p++) {
var acum = 0.0;
for (var i = 0; i < neuronasCapa[2]; i++) {
acum += errorSuma(peso: capas[2].neuronas[i].pesos[p]);
}
var w1kp = capas[1].neuronas[p].pesos[k];
var a1p = capas[1].salidas[p];
acumular += w1kp * a1p * (1 - a1p) * acum;
}
var dE0 = dErrorUmbral(acumular, capas[0].salidas[k]);
capas[0].neuronas[k].nuevoUmbral =
ajustePeso(capas[0].neuronas[k].umbral, dE0);
}
// actualiza los pesos
for (var capa in capas) {
capa.actualiza();
}
}
}
Lógicamente, cada vez que se ejecuta el programa se consigue el aprendizaje en un número de ciclos distinto o incluso, dependiendo de la tasa de aprendizaje, del números de ciclos y de los valores aleatorios iniciales, puede terminar el proceso de entrenamiento sin haber conseguido un nivel adecuado de aprendizaje. Ejemplo de una ejecución donde el resultado ya es correcto en el ciclo 2800 pero el margen de error todavía se considera demasiado grande, por lo que continúa hasta el ciclo 2885 donde el tamaño del error cumple el criterio de parada:
TABLA XOR SALIDA VALOR ERROR
Ciclo: 1
1 | 1 | 0 | 1 0.90460 0.90460
1 | 0 | 1 | 1 0.89226 0.10774
0 | 1 | 1 | 1 0.89409 0.10591
0 | 0 | 0 | 1 0.88837 0.88837
Ciclo: 400
1 | 1 | 0 | 1 0.50481 0.50481
1 | 0 | 1 | 0 0.47099 0.52901
0 | 1 | 1 | 1 0.50255 0.49745
0 | 0 | 0 | 1 0.52594 0.52594
Ciclo: 800
1 | 1 | 0 | 1 0.50809 0.50809
1 | 0 | 1 | 0 0.47510 0.52490
0 | 1 | 1 | 1 0.50274 0.49726
0 | 0 | 0 | 1 0.51821 0.51821
Ciclo: 1200
1 | 1 | 0 | 1 0.51490 0.51490
1 | 0 | 1 | 0 0.47991 0.52009
0 | 1 | 1 | 1 0.50426 0.49574
0 | 0 | 0 | 1 0.50675 0.50675
Ciclo: 1600
1 | 1 | 0 | 1 0.53830 0.53830
1 | 0 | 1 | 0 0.49164 0.50836
0 | 1 | 1 | 1 0.51460 0.48540
0 | 0 | 0 | 0 0.47422 0.47422
Ciclo: 2000
1 | 1 | 0 | 1 0.64045 0.64045
1 | 0 | 1 | 1 0.57181 0.42819
0 | 1 | 1 | 1 0.58962 0.41038
0 | 0 | 0 | 0 0.29851 0.29851
Ciclo: 2400
1 | 1 | 0 | 1 0.62299 0.62299
1 | 0 | 1 | 1 0.64681 0.35319
0 | 1 | 1 | 1 0.62830 0.37170
0 | 0 | 0 | 0 0.14900 0.14900
Ciclo: 2800
1 | 1 | 0 | 0 0.12268 0.12268
1 | 0 | 1 | 1 0.90098 0.09902
0 | 1 | 1 | 1 0.90021 0.09979
0 | 0 | 0 | 0 0.08031 0.08031
Ciclo: 2885 - Aprendizaje completado.
1 | 1 | 0 | 0 0.09972 0.09972
1 | 0 | 1 | 1 0.91850 0.08150
0 | 1 | 1 | 1 0.91802 0.08198
0 | 0 | 0 | 0 0.06856 0.06856
Fin